
Share to Facebook Share to Twitter Share to Linkedin For the first time, NVIDIA did not sweep the MLPerf table. While the era of its performance dominance may have come to an end, NVIDIA GPU’s flexibility and massive software ecosystem will continue to form a deep and wide moat. Meanwhile, Google, Intel, and Graphcore have achieved an important step in their attempts to cross that moat: excellent performance, good software, and ability to scale.
For decades, CPU vendors would leapfrog each other running benchmarks such as SPEC and TPC, with Intel, SUN SPARC, DEC Alpha, MIPS, and IBM POWER showing off the latest silicon. However the AI accelerator race has been a one-company story since the beginning, with NVIDIA far in front of a small pack of earnest wannabe’s. With MLPerf 2.
0, that has all changed. In a game of leapfrog, the winner is often determined by the timing of the comparison; we expect the next-gen Hopper GPU will retake the crown, but this time will not keep it. ADVERTISEMENT If you are tight for time, we suggest you skip the analyses and jump to the section on software near the end; that’s where this battle will be won or lost.
So, who is the winner? Well, it’s complicated. MLCommons just published the V2. 0 version of its AI training benchmark suite, with impressive performance gains as companies release new chips, including the Intel Habana Gaudi 2.
0, Google’s TPUv4, and Graphcore’s “BOW” platform with Wafer on Wafer technology. More important than the silicon, software performance improved even more dramatically, by over 30%. And startup MosaicML demonstrated its prowess in AI training optimization.
The results are difficult to present in an apples to apples fashion, as submitters naturally pick and choose specific configurations across the eight AI models being characterized, especially when it comes to the number of chips used in the training run. NVIDIA claims leadership in some benchmarks, while Google, Intel and Graphcore all claim leadership on at least one metric. ADVERTISEMENT Open MLPerf Training 2.
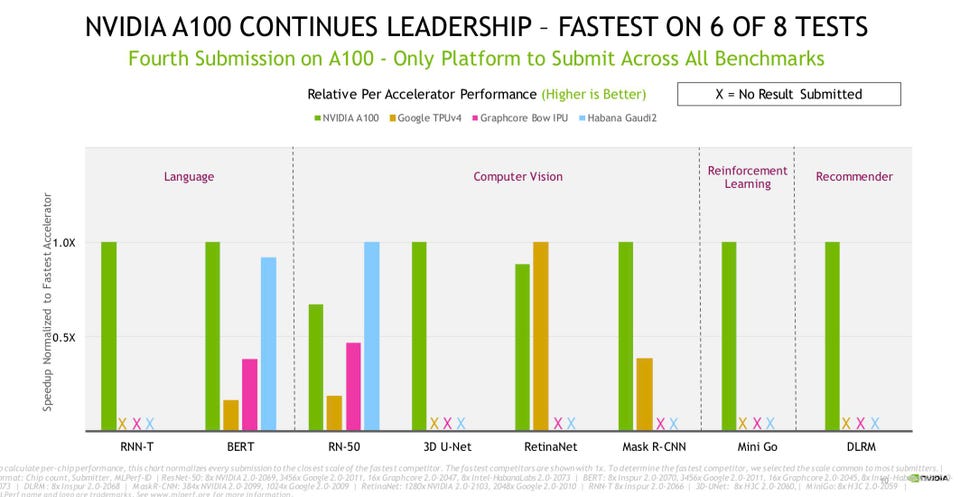
0 Results NVIDIA The graph above best summarizes the results for each architecture on a chip-to-chip basis for the eight benchmarks in MLPerf 2. 0 normalized to the fastest. Note that NVIDIA was the only company to submit across all eight benchmarks, which makes it easy for them to claim leadership on the 4 benchmarks no one contested, in addition to BERT and Mask R-CNN.
More on this later. For the very first time, Intel Habana and Google each won a benchmark on a chip-to-chip compare (ResNet-50 and RetinaNet respectively). However if you change the metric from “Fastest Chip” to “Fastest Results”, then you are really measuring how much a vendor is willing to spend to provide a massive research platform, and of course to squash its competitors.
In this case, Google is now the champion, but only on one benchmark. But if one cares about money (how quaint!), then Graphcore merits a closer look as they claim significantly better price-performance, at least for ResNet-50. ADVERTISEMENT Confused yet? Me too.
So, instead of trying to slice and dice the MLPerf 2. 0 spreadsheet to derive a rather useless comparison, let me summarize a few takeaways for each vendor. Google Google is to be congratulated on the TPUv4 and the TensorFlow software that goes along with it.
After three fairly disappointing attempts at TPU chips, the 4th generation looks like a winner. For image processing, a 4096 TPUv4 supercomputer beat the 4216 GPU NVIDIA Selene by some 40%. While these results are impressive, benchmarking at Google is really just an expensive sideshow.
For exascale computers, nobody would forgo a GPU’s more general purpose capabilities for a faster TPUv4 for AI. More to the point, Google’s penetration of cloud AI services is probably low because as a CSP, even Google Cloud surely prefers the flexibility, high utilization, and broad software ecosystem of an NVIDIA GPU SuperPod for their cloud clients. The performance chart below, from Google’s MLPerf blog, is indeed impressive, however I would note that the DLRM and BERT results for recommendation and NLP are only marginally better than NVIDIA, and these apps are increasingly where the money is.
Also, as is the case for all these comparisons, the Ampere A100 GPU is over 2 years old now, and the NVIDIA Hopper GPU is now sampling to customers with its new Transformer Engine . ADVERTISEMENT Google claims five winning benchmarks across the field, with up to 80% over NVIDIA’s A100. Google The real story here is that Google engineers designed an architecture to best meet their needs for internal applications such as search, translation, and recommendation.
And that design is the TPU. TPUv4’s will certainly reduce the demand for GPUs to run these internal apps, but will likely not displace much business from NVIDIA on the Google Cloud Platform. Graphcore UK Unicorn Graphcore also has a new chip to show off.
BOW, the company’s 3rd generation accelerator uses Wafer-on-Wafer technology to reduce latencies and power consumption. In general, it looks to me that the BOW platform delivers about 40% of the per-chip performance of a single A100 80 GB, as the image below compares a 16-node BOW POD 16 to an 8-GPU DGX. Keep in mind that this is ResNet-50, which has no business value we know of outside being a very popular Convolutional Neural Network all chips must run well for comparison sake.
ADVERTISEMENT Graphcore likes to compare their 16-chip results to NVIDIA’s 8-chip DGX A100. Graphcore While I applaud the Graphcore teams solid work on MLPerf, it really doesn’t tell the whole story of Graphcore’s differentiation , which is about price-performance and configuration flexibility using disaggregated CPUs and accelerators. In the figure below, Graphcore claims that 64 A100 GPUs are more expensive than a 256-node Graphcore POD which delivers some 40% more performance.
Graphcore appears to offer the best price-performance at scale, at least with Resnet Graphcore ADVERTISEMENT Baidu also submitted results to MLCommons using BOW, producing nearly identical results to those submitted by Graphcore. This leads us to two important thoughts. First, it means that Baidu was able to easily optimize the code for BOW.
Second, it means that Graphcore has caught the attention of China’s largest AI company. We will have to wait to see any confirmation of deployment of BOW at Graphcore, but Baidu looks like a likely design win for Graphcore, in our opinion. Habana After spending some $2B to acquire Israeli startup Habana Labs, Intel is finally starting to realize its goal of becoming the leading alternative to NVIDIA GPUs for AI.
Amazon AWS has started offering the Gaudi platform on AWS, and Habana has launched its second generation training platform which does a much better job at running MLPerf benchmarks than its predecessor. But a 7-36% advantage is unlikely to beat NVIDIA for most customers, especially since Hopper is around the corner. Habana Labs Gaudi 2 beat NVIDIA by 7-36%.
Intel ADVERTISEMENT BUT, and this is a huge but, Habana continues to tout unoptimized code or models, preferring to market “out of the box” ease of use. Now, we agree that some clients will not want to take the time or have the expertise to optimize AI for a specific chip, especially early in the selection process. But Habana is fighting the battle with one hand tied behind their back! For example, NVIDIA has demonstrated up to ten-fold improvements through software optimization.
Graphcore points to a 37% performance improvement between MLPerf 1. 1 and 2. 0.
Why spend hundreds of millions of dollars to develop a chip that doubles your performance if you are not going to finish the job with better software and increase your customer value by, say, 5X? We would rather see Habana give customers the choice of out of the box or optimized code. NVIDIA Ok, we are so used to hearing NVIDIA’s team proudly show how they trounced the competition, this week was a bit disorienting. And we all wanted to hear about Hopper! While that chip is still awaiting a production ramp, NVIDIA only won 2 benchmarks in head-to-head competition this time around.
However, NVIDIA submitted four other benchmarks with no challenger whatsoever. That’s either because the competition didn’t fare well in these, or more likely because they didn’t have the resources to stand up the code and optimize the results. Either way, we count this as a win for the green team.
Also, note that 90% of all MLPerf V2. 0 submissions were run on NVIDIA hardware, many submitted by over 20 partners from startup MosaicML to Baidu, Dell, HPE and others. ADVERTISEMENT To paraphrase political analyst James Carville from 1992, “Its the Ecosystem, stupid.
” The Back Story: Software If you strip away all the hardware hype, the real performance hero over time is the software that runs on these chips. NVIDIA points to some 14-23X performance improvement over the last 3. 5 years, and a whopping 23X over the last 3.
5 years, only a small part of which is the A100 over the V100. Graphcore points to a 37% improvement since V1. 1 (part of which is the BOW technology to be sure).
And to solve a customer’s problem you need a software stack that exploits your hardware advantages over many different AI models. This is where NVIDIA excels, in addition to having good hardware. The example they shared is below, in which a simple voice query can require nine AI models to produce an answer.
ADVERTISEMENT NVIDIA points out that it take nine different AI Models to answer a voice query about an image. NVIDIA If Intel is right, and people don’t want to mess with optimizations, can the optimization development process be streamlined? Could it be outsourced? After all, people don’t want to optimize benchmarks. They need to optimize real world applications that produce business results.
And each model and dataset is unique. Enter MosaicML and Codeplay . The latter, a champion of SYCL, was just acquired by Intel for OneAPI.
The former was formed by Naveen Rao, formerly of Intel and early AI startup Nervana. MosaicML’s mission is to “make AI model training more efficient for everyone”. They achieved astonishing results in their first MLPerf publication, beating NVIDIA’s optimized model by 17%, and the unoptimized model by 4.
5x. MosaicML improved performance over unoptimized ResNet-50 by 4. 5X, and 17% better than optimized .
. . [+] MXNet performance.
MosaicML ADVERTISEMENT Is this magic? Can it be repeatable? Is in invasive? The company’s blogs says “Our techniques preserve the model architecture of ResNet-50, but change the way it is trained. For example, we apply Progressive Image Resizing, which slowly increases the image size throughout training. These results demonstrate why improvements in training procedure can matter as much, if not more, than specialized silicon or custom kernels and compiler optimizations.
Deliverable purely through software, we argue that these efficient algorithmic techniques are more valuable and also accessible to enterprises. ” We will be watching as MLPerf tackles more models and helps more customers meet their ROI goals with AI projects. Conclusions Ok, this blog took a lot more work than normal, because each company has a good story to tell, but also a blind side.
If you made it to the software story, thank you. We congratulate the teams who worked so hard to submit these results, and the MLCommons team who herds the cats. We hope to see more team join the party in the next release in six months.
Customers need these important data points to inform their decisions and shape their perspectives. And the work to optimize these common AI workloads for MLPerf directly benefits customers in their AI journey. ADVERTISEMENT (AMD, we hope you are listening!).
From: forbes
URL: https://www.forbes.com/sites/karlfreund/2022/06/30/nvidia-loses-the-ai-performance-crown-at-least-for-now/